中文 Markdown 强调标记的渲染问题
在与 AI 对话的过程中,你一定见过这样不伦不类的输出:

换言之,那些本该加粗的部分并没有加粗,周围却多了一堆星号。
有一定技术背景的读者都知道,这些星号是 Markdown 中的强调标记。Markdown 是一种格式标记语言,可以用一些简单而直观的语法,为纯文本附加格式信息。近年来,Markdown 文档常用于模型训练,从而成为了 AI 模型的原生语言。如今,AI 模型的回答大多都是以 Markdown 格式输出,然后再在客户端渲染为带格式文本的。
当然,上述问题并不只出现在 AI 聊天中。如果你用 Markdown 记笔记或者写作,应当对类似的现象早就不陌生了。
可是,Markdown 语法不就是把 ** 之间的内容当作强调部分的吗?为什么在一些场景下能加粗,另一些场景下就不能加粗了呢?
答案是,「** 之间的是加粗部分」只是一种简略说法,当下流行的 Markdown 标准已经给这个规则追加了很多例外。遗憾的是,虽然新规则本意是让 Markdown 更加严谨,但却没有考虑中文的特殊性,导致一些本应生效的强调无法正常渲染。
来龙去脉要从 2004 年说起。当 John Gruber 在那年发布原版 Markdown 时,并没有制定严谨的规范,只提供了一份非正式的语法说明和一个 Perl 脚本 Markdown.pl。
根据 Gruber 的语法说明,任何包裹在 * 或 _ 中的文本,转换后都将被包裹在 HTML 标签 <em> 中;包裹在 ** 或 __ 中的文本,转换后将被包裹在 HTML 标签 <strong> 中;唯一的例外是,如果 * 或 _ 的周围是空格,则原样输出。
事实上,如果你用 Markdown.pl 来渲染上面的问题案例:
perl Markdown.pl <<EOF
**重要:**请注意。
这是**「重要」**的内容。
EOF
会发现结果是完全正确的:
<p><strong>重要:</strong>请注意。</p>
<p>这是<strong>「重要」</strong>的内容。</p>
这当然不是因为 Gruber 中文十级,纯粹只是因为 Markdown.pl 的实现方式就是简单粗暴的正则表达式替换:
$text =~ s{ (\*\*|__) (?=\S) (.+?[*_]*) (?<=\S) \1 }
{<strong>$2</strong>}gsx;
$text =~ s{ (\*|_) (?=\S) (.+?) (?<=\S) \1 }
{<em>$2</em>}gsx;
对于一个标记语言来说,这样的规则和解析方式未免有些潦草。(当年的 Gruber 大概也没想到 Markdown 会有如今地位。)事实证明,原版 Markdown 确实留下了很多模糊地带和不理想的边缘场景。就拿涉及强调标记的场景来说,我们并不希望像 a*(b+c)*d 这样的数学式,或者 snake_case_var 这样的变量名中的 * 和 _ 被当作添加强调,但 Markdown.pl 显然不能处理这样的复杂性。
然而,Markdown.pl 在 1.0.1 版后再也没有更新。其后,出现了不下十种 Markdown 的扩展语法和各种语言的实现,相互多有抵牾。一群不满现状的 Markdown 爱好者启动了一个标准化项目,于 2014 年发布第一版 CommonMark 规范,获得了广泛采用。2017 年,GitHub 在制定自己的 Markdown 规范(GitHub Flavored Markdown)时,将其作为 CommonMark 的严格超集,即除了表格等少数语法扩展外,完全沿用 CommonMark 的其余规则。这也进一步巩固了 CommonMark 的地位。
目前,许多主流的 Markdown 转换库,包括 ChatGPT、Claude 网页版使用的 remark,Obsidian 使用的 turndown,以及 VS Code 使用的 markdown-it 等,都是基于 CommonMark 的实现。因此,要解释 Markdown 强调标记为何会在中文环境下失效,就要看 CommonMark 对于强调语法是如何规定的。
这部分规定见于 CommonMark 规范的第 6.2 节。原文相当晦涩,但简单来说,为了让强调标记的使用更加严谨,它要求强调标记必须紧贴(flank)文字内容,其间内容才能被视作强调部分。
为了在程序上实现这一点,CommonMark 引入了「左侧贴合」(left-flanking)和「右侧贴合」(right-flanking)两个概念。
具体而言,一串强调标记是「左侧贴合」的,当且仅当——
- 它的后面不是一或多个空白符;及
- 它的后面——
a. 不是一个标点符号;或
b. 是一个标点符号,而它的前面是一或多个空白符(例如She says, **“Nice to ...),或者一个标点符号(例如(**“As noted ...)。1
换言之,一串强调标记的后面应当紧接着文字,或者左括号、左引号这样的起始标点,才能被视为强调部分的开头。
类似地,一串强调标记是「右侧贴合」的,当且仅当——
- 它的前面不是一或多个空白符;及
- 它的前面——
a. 不是一个标点符号;或
b. 是一个标点符号,而它的后面是一或多个空白符(例如... to meet you,”** she says.),或者一个标点符号(例如... noted above.”**))。
换言之,一串强调标记的前面应当紧接着文字,或者右引号、右括号这样的结束标点,才能被视为强调部分的结束。
在此基础上,CommonMark 规定,只有处在「左侧贴合」的强调标记之后、「右侧贴合」的强调标记之前的文本,才能被视作强调内容。特殊地,如果使用 _ 或 __ 作为强调标记,要让强调生效,它不能同时构成左侧贴合和右侧贴合,除非它在被贴合内容的另一侧紧接着一个标点(例如 _What If?_.)。
由此,上文提到的这些边缘场景都会按原样渲染,而不会出现任何强调格式:
a*(b+c)*d
snake_case_var
在第一行中,前一个 * 的后面是标点符号,但它前面既不是标点符号也不是空白符,所以不是右侧贴合;类似地,后一个 * 也不是左侧贴合。因此,没有形成一个强调部分。在第二行中,两个 _ 的前后都是字母,而不是空白或标点,因此既是右侧贴合又是左侧贴合,也不能形成强调部分。
不难发现,当 CommonMark 试图以程序方式定义何为「紧贴文字」时,只考虑了英文等以空格分词的西方书写系统,因此大量依赖空格的语义功能来判断一段内容从何处开始、在何处结束。但一旦遇到中文这类词语之间没有空格的情况,就会出现很多不符合情理的判断。
回到上面的问题案例:
**重要:**请注意。
这是**「重要」**的内容。
在第一行中,后一对 ** 的前面是冒号,属于标点符号。根据定义,要构成右侧贴合,它的后面必须是空白符或者标点符号,而这里它的后面是汉字,从而不构成右侧贴合。在第二行中,前一对 ** 的后面是引号,同属标点符号。根据定义,要构成左侧贴合,它的前面必须是空白符或者标点符号,而这里它的前面也是汉字,从而不构成左侧贴合(类似地,后一对 ** 也不构成右侧贴合)。
因此,在这两个例子中,前后两对 ** 都无法形成强调部分,其间文本也就不会被加粗。
(另一个较为少见但成因类似的案例是夹在汉字之间的 _,即形如 这是__重要__的内容 的强调部分,因为前述针对 _ 的特别规则,也不会生效。)
以下是一些常见 Markdown 处理器的渲染效果对比,其中不能渲染出中文间强调标记的几种处理器都是采用了 CommonMark 规范:
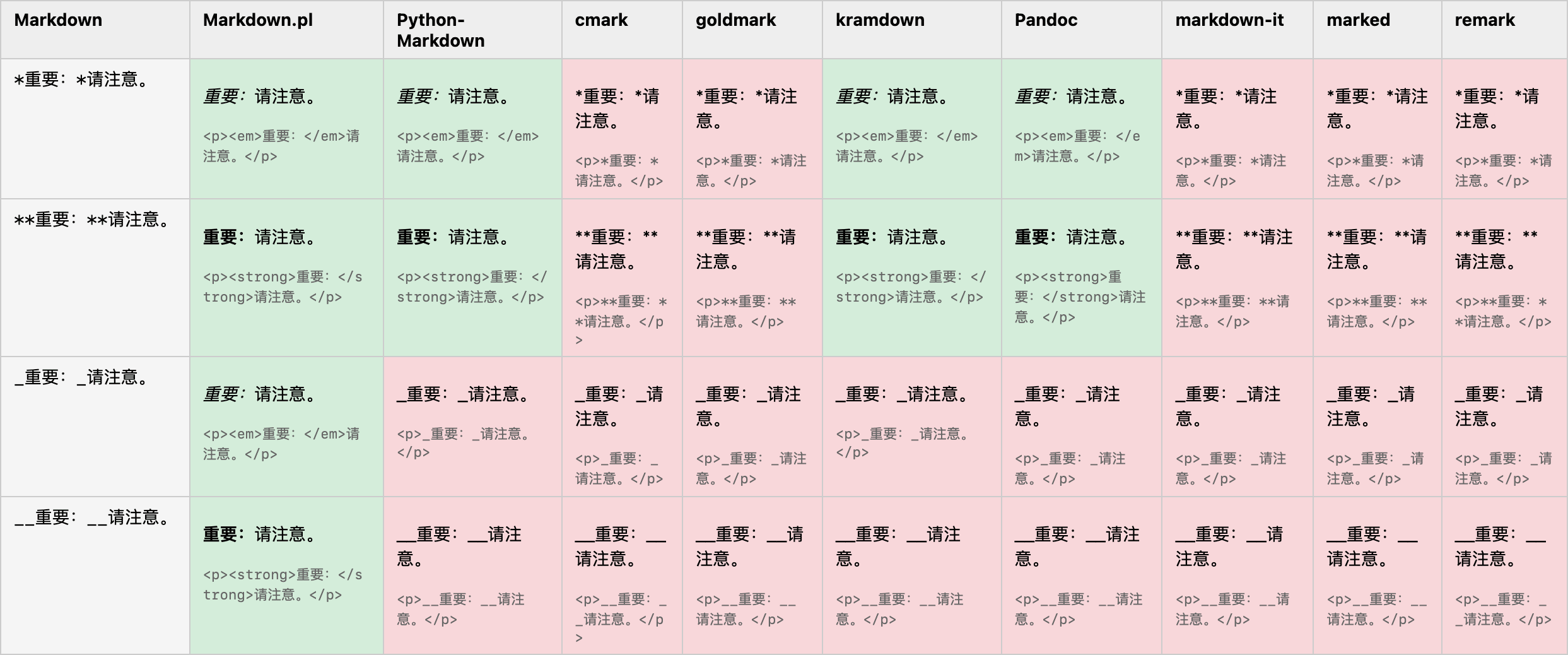
其实,早就有许多中日韩用户注意到了这个问题。至迟在 2017 年,CommonMark 社区中就有用户提报过东亚文字中的强调标记问题,并提交了一个合并请求,但最终并未获得采纳。根据一名 CommonMark 维护者的说法,CommonMark 把兼容既有 Markdown 放在首位,针对 CJK 的专属方案不太可能被纳入,除非能证明「对现存海量文档影响极小」。
因此,至少在短期内,大概仍然无法期待中文 Markdown 的渲染问题从上游获得修复。根据具体的使用场景,这里提出几种变通方法供参考。
第一种方法是使用 HTML 标签来创建强调。由于 Markdown 语法允许直接使用 HTML,可以将上面的问题案例改写成:
<strong>重要:</strong>请注意。
这是<strong>「重要」</strong>的内容。
这样就完全回避了 CommonMark 不适合中文的处理规则。这种做法最为直接,缺点是比较麻烦,也不太美观。
第二种方法是通过添加空格来变相满足 CommonMark 的要求,即写成([SPACE] 表示插入空格的位置):
**重要:**[SPACE]请注意。
这是[SPACE]**「重要」**[SPACE]的内容。
这样,原本不构成贴合的强调标记,由于空格的加入就成为贴合的了。有趣的是,有一些国外模型(特别是 Gemini),可能因为缺乏中文训练,会强迫症般地在中文冒号甚或句号后面加一个空格,导致输出结果「误打误撞」地可以正确加粗。(这也是一个识别 AI 生成文本的实用技巧。)
当然,在中文里加普通空格比较难看,也没有任何语义上的依据。相比之下,一种更为美观的做法是加入不占任何空间的零宽空格(U+200B ZERO WIDTH SPACE):
**重要:[ZWSP]**请注意。
这是**[ZWSP]「重要」[ZWSP]**的内容。
这里,[ZWSP] 表示插入零宽空格的位置。注意与普通空格不同,零宽空格不是 CommonMark 定义上的空白符,而是普通字符,因此要加在强调标记的内侧而不是外侧,才能使得强调标记变成贴合文本的。考虑到零宽空格本来就具有指示单词边界的功能,这么做在语义上也算说得过去,只是输入起来可能比较麻烦。如果采用这种方法,可能最好配合一些快捷输入方式(例如 macOS 的文本替换)或者自动化脚本。
此外,如果你是开发者,或者所用工具支持扩展,那么可以使用一些针对东亚文字优化的补丁。例如,markdown-cjk-friendly 项目修订了 CommonMark 规则,在解析强调标记时,将其外围的 CJK 字符视为与空白符有同等效果。它提供了适用于 markdown-it 和 remark 的插件,将其与这些库一起导入,即可在不影响其他 CommonMark 规则正确性的同时(markdown-cjk-friendly 可以通过所有 CommonMark 的现有测试),修复 CJK 文本中的 Markdown 强调标记问题。
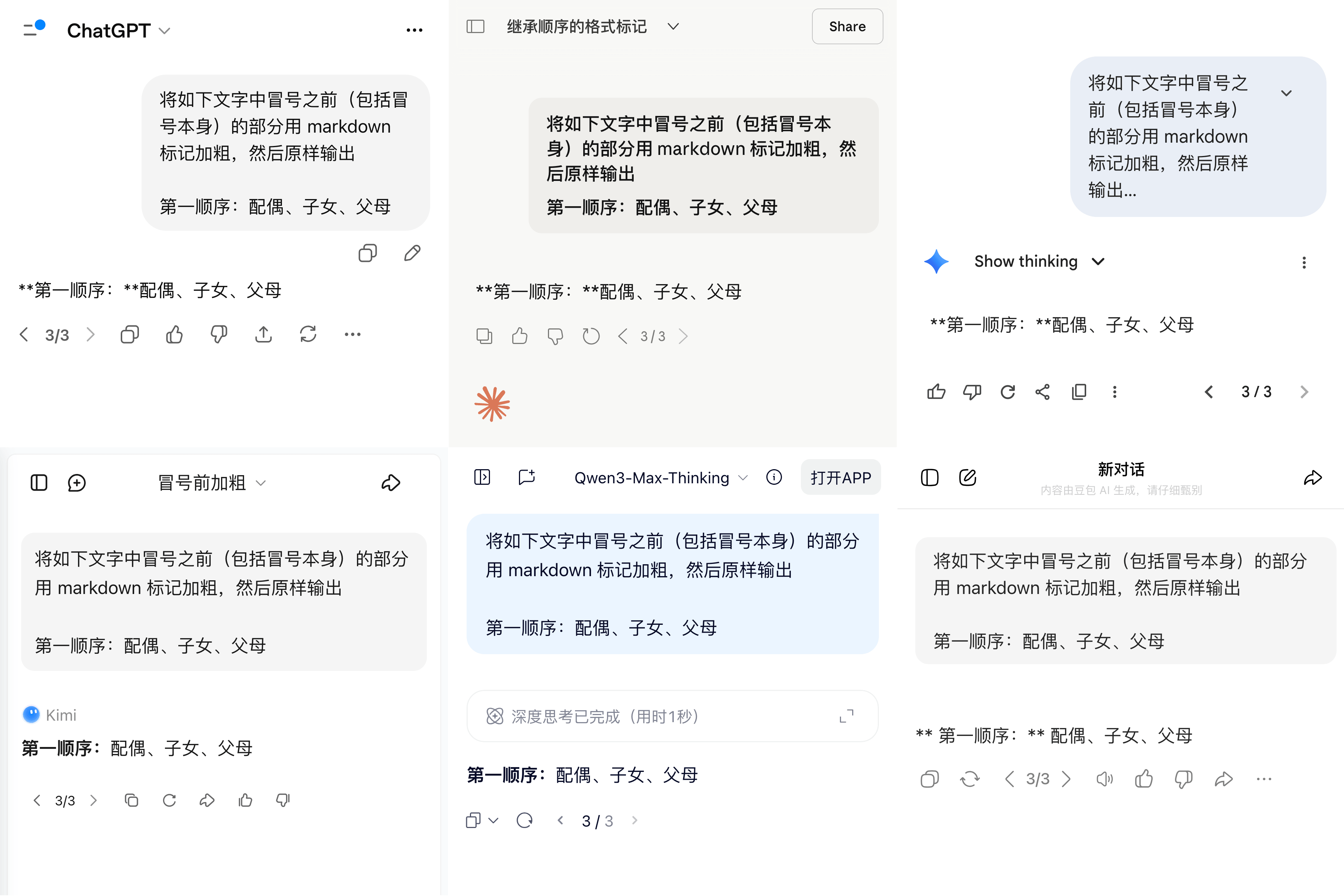
值得肯定的是,一些 AI 服务似乎已经注意到了这个问题。例如,国产的 Kimi 和豆包都能正确渲染夹在汉字之间的强调标记,即使它们使用的 markdown-it 遵循的也是 CommonMark,或许是专门做了处理;国外服务中的 Perplexity 也能正确渲染。
最后跑题一句,在思考如何修复强调格式的同时,也不妨花些时间思考是否真的有必要靠格式来制造强调——粗体并不是适合中文的强调方式,斜体中文更是最可怕的排版效果之一。如果条件允许,本文还是建议不要学习 AI 模型一言不合就加粗的坏习惯,尽量依靠句式、措辞和标点的变化来指示重点。毕竟,真正掷地有声的话是不需要靠吼的。
-
这里,「空白符」是指 Unicode 通用类别(general category)为 Zs (space character) 的字符(即各类空格),再加上制表符(U+0009)、换行符(U+000A)、换页符(U+000C)、回车符(U+000D),以及行首和行尾。「标点符号」是指 Unicode 通用类别为 P (puncuation) 或 S (symbol) 的字符。 ↩︎